v ggplot2 3.3.6 v purrr 0.3.4
v tibble 3.1.7 v dplyr 1.0.9
v tidyr 1.2.0 v stringr 1.4.0
v readr 2.1.2 v forcats 0.5.1
Warning: package 'ggplot2' was built under R version 4.1.3
Warning: package 'tibble' was built under R version 4.1.3
Warning: package 'tidyr' was built under R version 4.1.3
Warning: package 'readr' was built under R version 4.1.3
Warning: package 'dplyr' was built under R version 4.1.3
-- Conflicts ------------------------------------------ tidyverse_conflicts() --
x dplyr::filter() masks stats::filter()
x dplyr::lag() masks stats::lag()
library(brms)
Warning: package 'brms' was built under R version 4.1.3
Loading required package: Rcpp
Warning: package 'Rcpp' was built under R version 4.1.3
Loading 'brms' package (version 2.17.0). Useful instructions
can be found by typing help('brms'). A more detailed introduction
to the package is available through vignette('brms_overview').
Attaching package: 'brms'
The following object is masked from 'package:stats':
ar
library(bayesplot)
Warning: package 'bayesplot' was built under R version 4.1.3
This is bayesplot version 1.9.0
- Online documentation and vignettes at mc-stan.org/bayesplot
- bayesplot theme set to bayesplot::theme_default()
* Does _not_ affect other ggplot2 plots
* See ?bayesplot_theme_set for details on theme setting
library(ProbBayes)
Warning: package 'ProbBayes' was built under R version 4.1.3
Loading required package: LearnBayes
Attaching package: 'LearnBayes'
The following object is masked from 'package:brms':
rdirichlet
Loading required package: gridExtra
Attaching package: 'gridExtra'
The following object is masked from 'package:dplyr':
combine
Loading required package: shiny
Warning: package 'shiny' was built under R version 4.1.3
8.2 Multilevel modeleren met proportions
8.2.1 Ziekenhuis study
Tabel 10.2 geeft aantal gevallen en het aantal doden bij een hartaanval voor 13 ziekenhuizen in New York. Deze data zitten in het dataframe DeathHeartAttackManhattan in het ProbBayes pakket.
8.2.2 Een multilevel model
We gaan uit van een hierarchisch model zoals beschreven in Sectie 10.3.
Sampling
We nemen eerst aan dat \(yj\), het aantal sterfgevallen in het \(jde\) ziekenhuis, binomiaal is met steekproefgrootte #\(n_j\) en waarschijnlijkheid \(p_j\). Laat \(j_theta_j=log(\frac{p_j}{(1-p_j))\) de logit voor het \(jde\) ziekenhuis.
Schrijf \(\theta_j=\beta+\gamma_j\).
Prior
We nemen aan dat het intercept \(beta\) een student-t distributie heeft met gemiddelde 0, schaalparameter 2,5 en 3 vrijheidsgraden. We nemen aan dat \(gamma_i,....,\gamma_N\) normaal verdeeld zijn met gemiddelde 0 en standaardafwijking \(\sigma\).
De standaardafwijking \(\sigma\) wordt verondersteld een t-dichtheid te hebben met gemiddelde 0 en standaardafwijking 3.5.
8.2.3 Fitten van het Bayesiaanse model
We fitten het multilevelmodel met de brm() functie. Let op het gebruik van het “family = binomial” argument om de steekproefverdeling aan te geven. De component “(1|)” geeft aan dat de \(gamma_j\) een willekeurige verdeling heeft.
fit <-brm(data = DeathHeartAttackManhattan, family = binomial, Deaths |trials(Cases) ~1+ (1| Hospital),refresh =0)
Compiling Stan program...
Start sampling
We hebben geen priors opgegeven, maar er zijn standaard priors achter de schermen. De prior_summary() functie toont de priors.
8.2.4 Posterior samenvattingen van \(\beta\) en \(\sigma\)
De summary() functie toont posterior samenvattingen van \(beta\) (het intercept) en de standaardafwijking \(\sigma\).
summary(fit)
Family: binomial
Links: mu = logit
Formula: Deaths | trials(Cases) ~ 1 + (1 | Hospital)
Data: DeathHeartAttackManhattan (Number of observations: 13)
Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
total post-warmup draws = 4000
Group-Level Effects:
~Hospital (Number of levels: 13)
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sd(Intercept) 0.19 0.14 0.01 0.53 1.01 1146 1196
Population-Level Effects:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept -2.60 0.11 -2.81 -2.39 1.00 2560 1837
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).
8.2.5 Posterior samenvattingen van ziekenhuis effecten
De posterior_samples() functie produceert een grote matrix van gesimuleerde trekkingen waarbij de kolom overeenkomt met de parameter en de rij correspondeert met het iteratie nummer.
Door gebruik te maken van de pivot_longer() functie, formatteer ik de simulatie matrix waarbij er een nieuwe variabele Hospital is die de naam van het ziekenhuis en Effect is de gesimuleerde waarde van \(\gamma_y\). Ook heb ik een nieuwe variabele aan die het nummer van het ziekenhuis is, van 1 tot 13.
posterior_samples(fit) %>%pivot_longer(starts_with("r_Hospital"),names_to ="Hospital",values_to ="Effect") -> post
Warning: Method 'posterior_samples' is deprecated. Please see ?as_draws for
recommended alternatives.
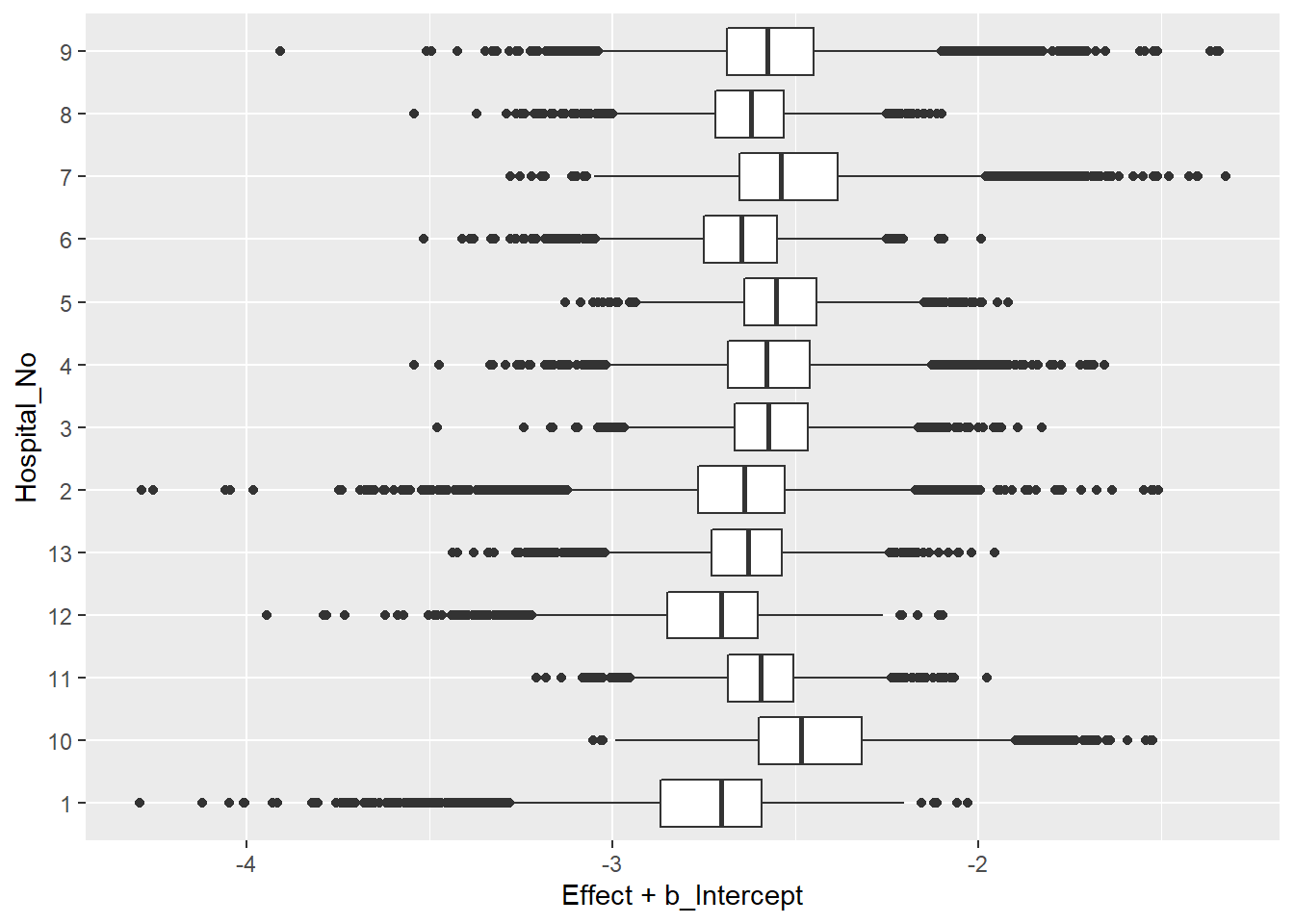
Hieronder zie je een grafiek van de posterior verdeling van de parameters voor alle 13 ziekenhuizen.
Deze zijn gegraveerd op de logit schaal. Door de inverse logit functie te nemen, kan men de posterior verdelingen van de sterftecijfers vinden \(p_1,....,p_N\).
Tabel 10.1 geeft samenvattingen van de beoordelingen voor acht verschillende animatiefilms. De tabel bevat het aantal beoordelingen, het gemiddelde en de standaardafwijking van de beoordelingen. De gegevens staan in het dataframe animation_rating in het ProbBayes pakket.
8.3.2 Het multilevel model
Sampling
Laat \(Y_ij\) de waardering van het \(ide\) individu voor de \(jde\) film.
We gaan uit van \(y_ij∼N(\mu, \sigma)\).
Prior
De parameters \(\mu_1,...,\mu_8\) vertegenwoordigen de gemiddelde ratings voor de acht films. Schrijf
\[\mu_j=\beta+\gamma_j\]
De intercept-parameter \(\beta\) heeft een student t-distributie met gemiddelde 4, schaalparameter 2.5, en 3 vrijheidsgraden.
We nemen aan dat de effectparameters \(gamma_1,...,\gamma_8\) een normale verdeling hebben met gemiddelde 0 en standaardafwijking \(τ\).
Er zijn twee standaardafwijkingen, de samplingstandaardafwijking \(\sigma\) en de tussen-gemiddelde standaardafwijking \(τ\). Elk van deze standaardafwijkingen krijgen zwak informatieve student t-verdelingen met gemiddelde 0, schaal 2,5 en 3 vrijheidsgraden.
8.3.3 Bayesiaans fitten
Het model wordt gefit door gebruik te maken van de brm() functie. Standaard gaat deze functie standaard uit van een Gaussische (normale) steekproefverdeling. Het argument “(1|movieID)” argument geeft aan dat de `brmu_1,…,_8$ een willekeurige verdeling hebben.
fit <-brm(rating ~ (1| movieId),data = animation_ratings,refresh =0)
Compiling Stan program...
Start sampling
Warning: There were 1 divergent transitions after warmup. See
https://mc-stan.org/misc/warnings.html#divergent-transitions-after-warmup
to find out why this is a problem and how to eliminate them.
Warning: Examine the pairs() plot to diagnose sampling problems
Men kan de standaard priors controleren met behulp van de prior_summary() functie.
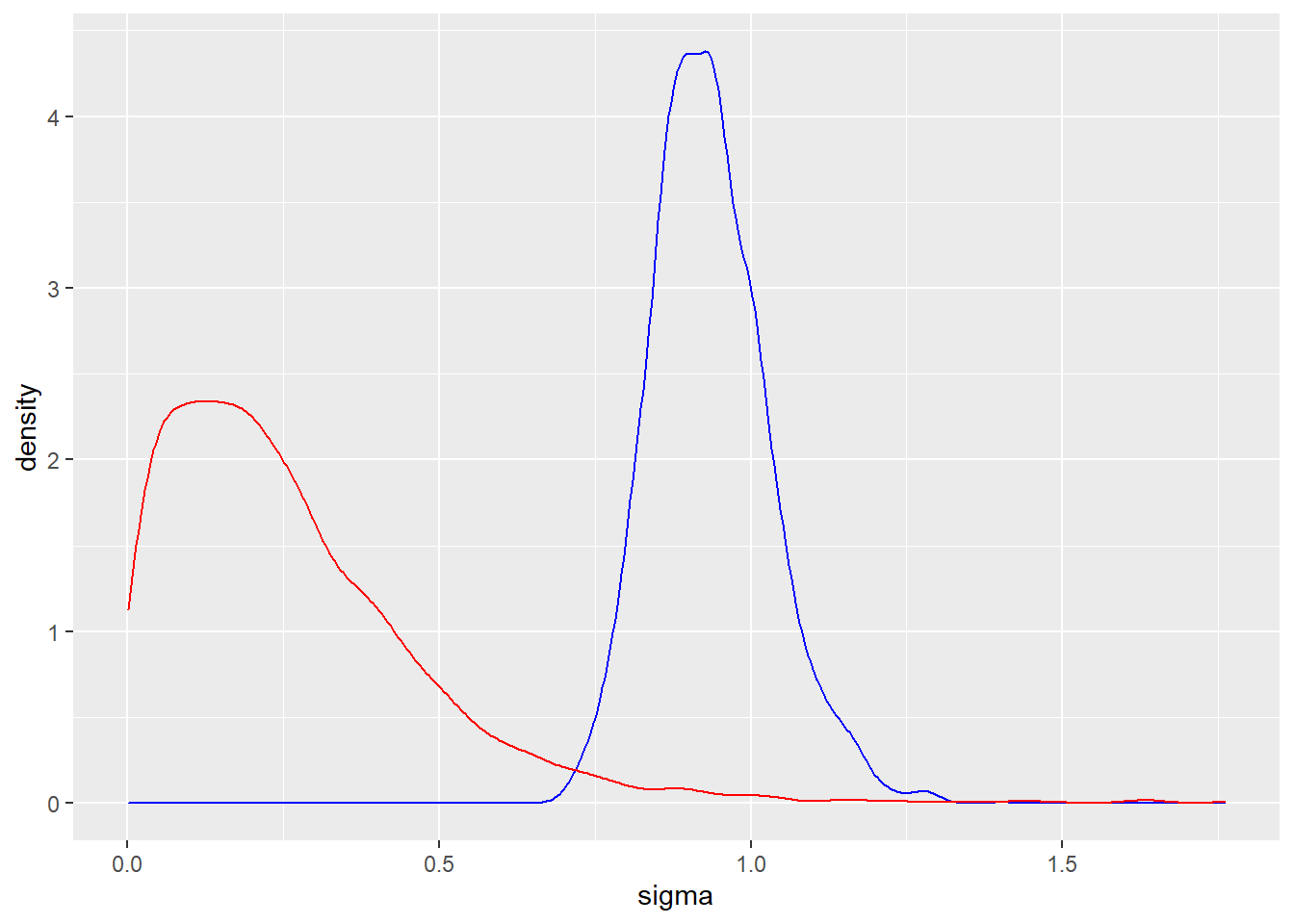
De posterior matrix van gesimuleerde trekkingen is beschikbaar door gebruik te maken van de posterior_samples() functie. Hieronder construeer ik dichtheidsschattingen van de twee standaardafwijkingsparameters $\(sigma\) (blauw) en \(τ\) (rood).
Warning: Method 'posterior_samples' is deprecated. Please see ?as_draws for
recommended alternatives.
Om de posterior verdelingen van de gemiddelden te tonen, vervorm ik de matrix van gesimuleerde trekkingen door gebruik te maken van de pivot_longer() functie.
posterior_samples(fit) %>%pivot_longer('r_movieId[76093,Intercept]':'r_movieId[81847,Intercept]',names_to ="Movie",values_to ="Effect") -> post
Warning: Method 'posterior_samples' is deprecated. Please see ?as_draws for
recommended alternatives.
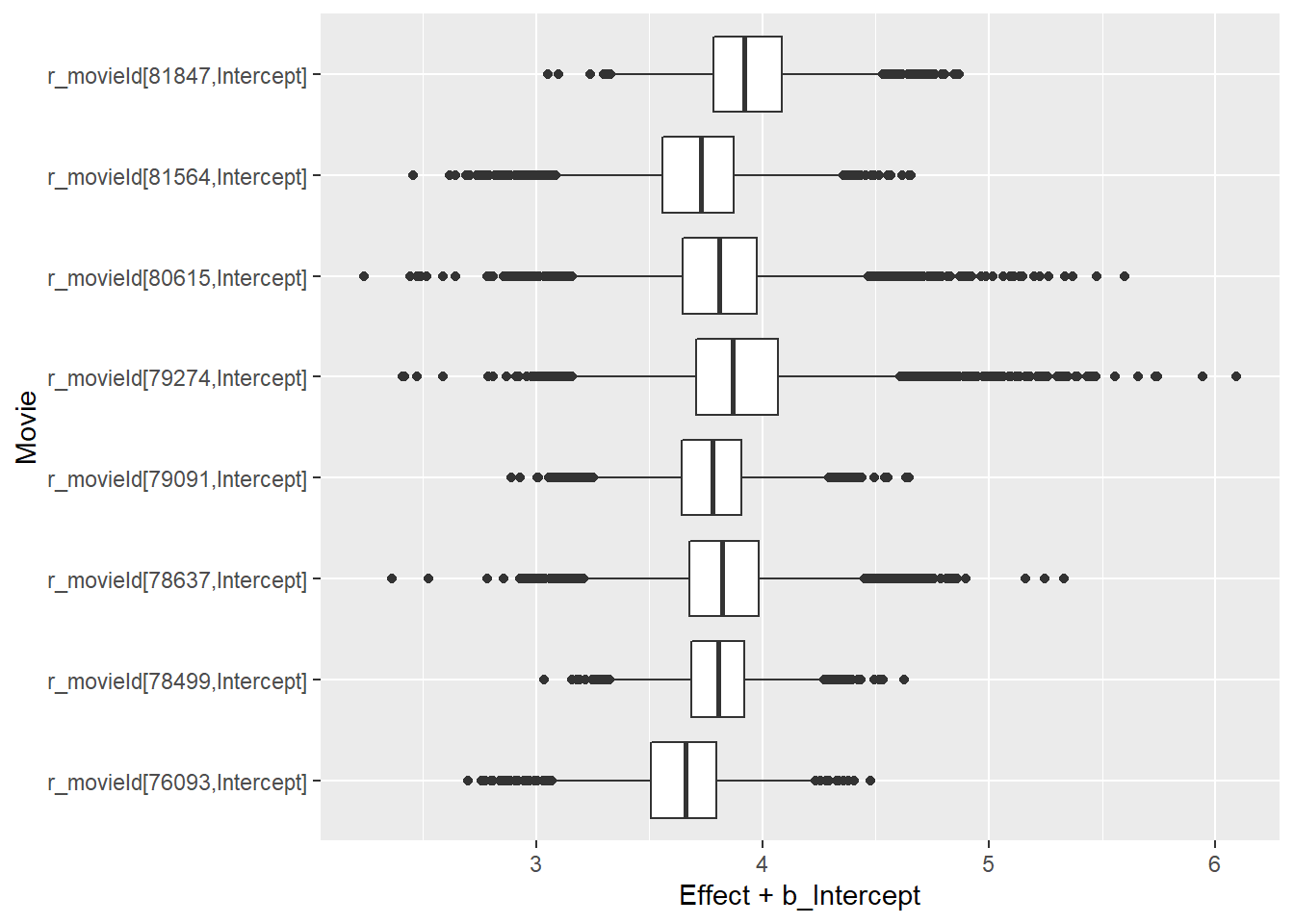
Onthoud dat we de gemiddelde filmwaardering hebben voorgesteld als \(\mu_j=\beta + \gamma_j\). Hieronder staan parallelle boxplots van de posterior verdelingen van \(mu_1,...,\mu_8\).