v ggplot2 3.3.6 v purrr 0.3.4
v tibble 3.1.7 v dplyr 1.0.9
v tidyr 1.2.0 v stringr 1.4.0
v readr 2.1.2 v forcats 0.5.1
Warning: package 'ggplot2' was built under R version 4.1.3
Warning: package 'tibble' was built under R version 4.1.3
Warning: package 'tidyr' was built under R version 4.1.3
Warning: package 'readr' was built under R version 4.1.3
Warning: package 'dplyr' was built under R version 4.1.3
-- Conflicts ------------------------------------------ tidyverse_conflicts() --
x dplyr::filter() masks stats::filter()
x dplyr::lag() masks stats::lag()
library(brms)
Warning: package 'brms' was built under R version 4.1.3
Loading required package: Rcpp
Warning: package 'Rcpp' was built under R version 4.1.3
Loading 'brms' package (version 2.17.0). Useful instructions
can be found by typing help('brms'). A more detailed introduction
to the package is available through vignette('brms_overview').
Attaching package: 'brms'
The following object is masked from 'package:stats':
ar
library(bayesplot)
Warning: package 'bayesplot' was built under R version 4.1.3
This is bayesplot version 1.9.0
- Online documentation and vignettes at mc-stan.org/bayesplot
- bayesplot theme set to bayesplot::theme_default()
* Does _not_ affect other ggplot2 plots
* See ?bayesplot_theme_set for details on theme setting
library(ProbBayes)
Warning: package 'ProbBayes' was built under R version 4.1.3
Loading required package: LearnBayes
Attaching package: 'LearnBayes'
The following object is masked from 'package:brms':
rdirichlet
Loading required package: gridExtra
Attaching package: 'gridExtra'
The following object is masked from 'package:dplyr':
combine
Loading required package: shiny
Warning: package 'shiny' was built under R version 4.1.3
7.1 Verhoudingen vergelijken
7.1.1 Vergelijken van twee Poisson verhoudingen
Stel we vergelijken twee onafhankelijke samples: \(x_1,...,x_m\) is een random sample van een Poisson distributie met gemiddelde \(\lambda_x\), en \(w_1,...,w_n\) is een random sample van een Poisson distributie met gemiddelde \(\lambda_y\). We willen van de ratio van de Poisson gemiddelde \[\theta=\frac{\lambda_x}{\lambda_y}\] leren
7.1.2 Schrijf het als een log-lineair model
Stel we verzamelen de observaties
\[y=c(x_1, ...,X_m,W_1...,w_n)\]
en laat group2een indicatorvariabele zijn voor de tweede groep.
\[group2=c(0,0,...,0,1,1,...,1)\]
Dan representeren we het model als
\[u_1,...,y_m+n\]
onafhankelijk van de Poisson-distributies met gemiddelden \(\lambda_1,..., \lambda_m_n\)$ waarbij de gemiddelden een log-lineair model volgen van
\[log\lambda_j=\beta_0 + \beta_1group2\]
In dit model hebben we \(\beta_0=log\lambda_x\), en \(\beta_0+\beta_1=log\lambda_y\). Dus \(\beta_1=log(\lambda_y)-log(\lambda_x)\) representeert de toename van het gemiddelde op de log schaal.
7.1.3 De data
We verzamelen aantallen webbezoeken voor een aantal dagen opgeslagen in het dataframe web_visits in het ProbBayes pakket. De sleutelvariabelen zijn Day, de dag van de week, en Count, het aantal websitebezoeken. We definiëren een nieuwe variabele Type dat is of “weekend” of “dag door de week”.
We zijn geïnteresseerd in het vergelijken van gemiddelde bezoeken in het week of op andere anderen in de week.
Hier gaan we uit van zwak informatieve priors op de regressie parameters \(\beta_0\) en \(\beta_1\).
7.1.5 Bayesiaans fitten
fit <-brm(Count ~ Type,family = poisson,data = web_visits,refresh =0)
Compiling Stan program...
Start sampling
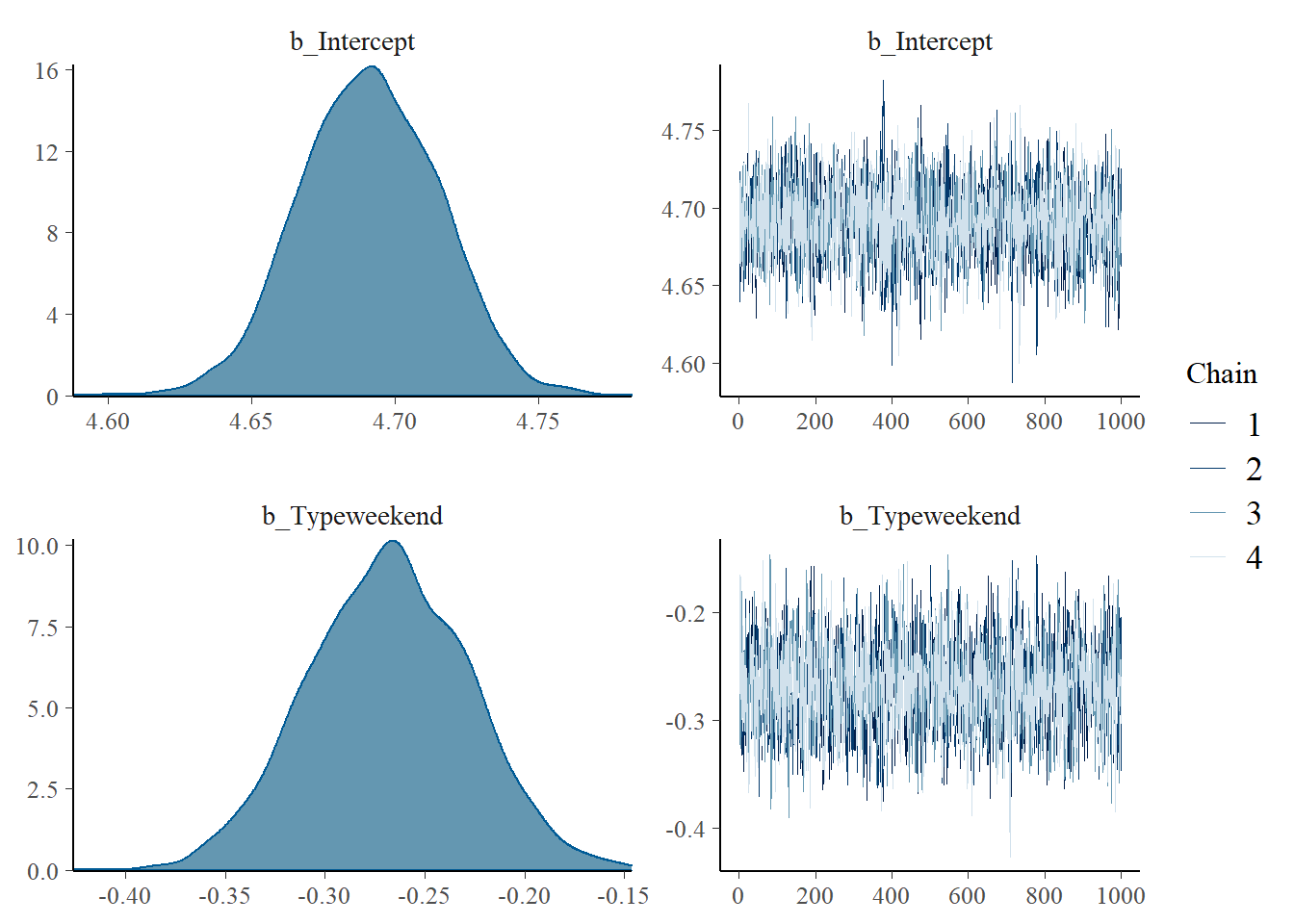
plot(fit)
summary(fit)
Family: poisson
Links: mu = log
Formula: Count ~ Type
Data: web_visits (Number of observations: 28)
Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
total post-warmup draws = 4000
Population-Level Effects:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept 4.69 0.02 4.64 4.74 1.00 3751 2736
Typeweekend -0.27 0.04 -0.35 -0.19 1.00 3148 2028
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).