v ggplot2 3.3.6 v purrr 0.3.4
v tibble 3.1.7 v dplyr 1.0.9
v tidyr 1.2.0 v stringr 1.4.0
v readr 2.1.2 v forcats 0.5.1
Warning: package 'ggplot2' was built under R version 4.1.3
Warning: package 'tibble' was built under R version 4.1.3
Warning: package 'tidyr' was built under R version 4.1.3
Warning: package 'readr' was built under R version 4.1.3
Warning: package 'dplyr' was built under R version 4.1.3
-- Conflicts ------------------------------------------ tidyverse_conflicts() --
x dplyr::filter() masks stats::filter()
x dplyr::lag() masks stats::lag()
library(brms)
Warning: package 'brms' was built under R version 4.1.3
Loading required package: Rcpp
Warning: package 'Rcpp' was built under R version 4.1.3
Loading 'brms' package (version 2.17.0). Useful instructions
can be found by typing help('brms'). A more detailed introduction
to the package is available through vignette('brms_overview').
Attaching package: 'brms'
The following object is masked from 'package:stats':
ar
library(bayesplot)
Warning: package 'bayesplot' was built under R version 4.1.3
This is bayesplot version 1.9.0
- Online documentation and vignettes at mc-stan.org/bayesplot
- bayesplot theme set to bayesplot::theme_default()
* Does _not_ affect other ggplot2 plots
* See ?bayesplot_theme_set for details on theme setting
library(ProbBayes)
Warning: package 'ProbBayes' was built under R version 4.1.3
Loading required package: LearnBayes
Attaching package: 'LearnBayes'
The following object is masked from 'package:brms':
rdirichlet
Loading required package: gridExtra
Attaching package: 'gridExtra'
The following object is masked from 'package:dplyr':
combine
Loading required package: shiny
Warning: package 'shiny' was built under R version 4.1.3
6.1 Proporties vergelijken
6.1.1 Facebook gebruik, voorbeeld
In Hoofdstuk 9 van Alberts en Hu’s boek vergelijken ze de volgende proporties. Een sample studenten is gevraagd naar hun geslacht en het gemiddeld aantal keren dat ze op een dag Facebook bezoeken.
Van de \(n_M\) mannen in de sample had \(y_M\) een hoog aantal Facebook bezoeken en van de \(n_F\) vrouwen in de sample had \(y_F\) een hoog aantal bezoeken.
Stel dat de data zijn georganiseerd als het volgende dataframe:
In dit model is \(\beta_0\) de logit van het aandeel vrouwen dat veel Facebook gebruikt en \(\beta_1\) het verschil in de logits van de proporties voor mannen en vrouwen.
Veronderstel dat je niet veel weet over de locatie van \(beta_0\), maar je denkt dat mannen en vrouwen gelijkaardig zijn in hun gebruik van Facebook. Dus je kent u een N(0, 31.6) toe aan \(\beta_0\) met een hoge standaardafwijking, wat weinig kennis weergeeft. Om de overtuiging weer te geven dat \(\beta_1\) dicht bij 0 ligt, gebruik je een \(N(0, 0.71)\) prior.
De get_prior() functie geeft een lijst van alle parameters om priors op te definiëren voor dit specifieke model, en kent het resultaat toe aan de prior. Dan worden de twee componenten van de prior toegewezen die de bovenstaande verklaringen weergeven.
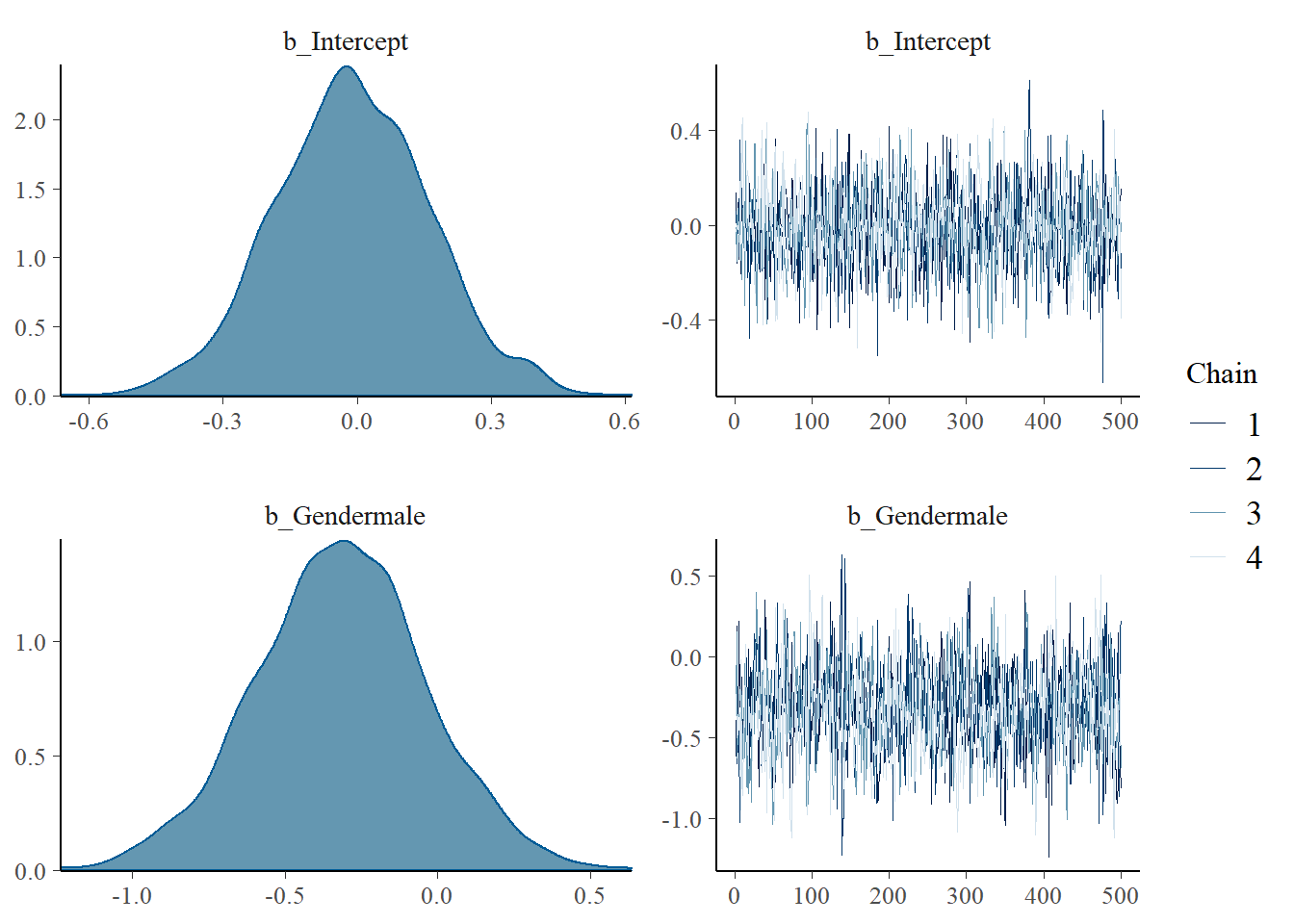
De plot() functie geeft de traceplots en densityplots van elke parameter.
plot(fit)
Posterior samenvattingen krijg je met de print() functie.
print(fit)
Family: binomial
Links: mu = logit
Formula: Visits | trials(Sample_Size) ~ Gender
Data: fb_data (Number of observations: 2)
Draws: 4 chains, each with iter = 1000; warmup = 500; thin = 1;
total post-warmup draws = 2000
Population-Level Effects:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept -0.01 0.17 -0.35 0.35 1.00 2052 1348
Gendermale -0.32 0.28 -0.88 0.23 1.00 1049 1154
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).